面向对象与函数式编程设计模式
引子
坊间传闻很多程序员之间的鄙视链,我们虽然可以不以为然,但也常常不能免俗。在今天的面向对象设计与函数式编程的上下文中套用一下鄙视链的逻辑,可能是懂 Functional Programming 的工程师鄙视老是把设计模式挂在嘴边的工程师,老是把设计模式挂在嘴边的工程师鄙视会说「你这样写就不 OO 了啊」的工程师,会说「你这样写就不 OO 了啊」的工程师鄙视会说「蛤?什么面向对象?不是把重复的 code 写成一个 function 就好了吗?」的工程师,会说「蛤?什么面向对象?不是把重复的 code 写成一个 function 就好了吗?」的工程师鄙视把同一段 code 到处复制贴上的工程师。那么什么是面向对象,什么是函数式编程?他们之间又有怎样的关系呢?
索引
概念
什么是面向对象?看下维基百科的定义: 面向对象编程(英语:Object-oriented programming,缩写:OOP)是种具有对象概念的程序编程范型,同时也是一种程序开发的方法。它可能包含数据、属性、代码与方法。对象则指的是类的实例。它将对象作为程序的基本单元,将程序和数据封装其中,以提高软件的重用性、灵活性和扩展性,对象里的程序可以访问及经常修改对象相关连的数据。在面向对象程序编程里,计算机程序会被设计成彼此相关的对象。
什么是函数式编程?维基百科的定义:函数式编程(英语:functional programming)或称函数程序设计,又称泛函编程,是一种编程范型,它将计算机运算视为数学上的函数计算,并且避免使用程序状态以及易变对象。函数编程语言最重要的基础是λ演算(lambda calculus)。而且λ演算的函数可以接受函数当作输入和输出。比起命令式编程,函数式编程更加强调程序执行的结果而非执行的过程,倡导利用若干简单的执行单元让计算结果不断渐进,逐层推导复杂的运算,而不是设计一个复杂的执行过程。
面向对象与函数式编程对比(OO VS FP)
从起源来看,面向对象来源于生物学,将程序用对象的形式来表示。而函数式编程来源于数学(具体是lambda演算)。 而OO和FP的被人们广泛应用则是分别是因为GUI应用和并行计算的兴起。从程序的组织形式上看,OO和FP编程范式的程序的基本单位分别是对象和函数,OO是指令式编程,而FP是声明式编程。OO的代表语言有C++,Java,Objective-C, C#,而FP的代表语言有Haskell,Scheme,Erlang,而另外一些编程语言(如JavaScript和Python)既可以采用面向对象编程又可以采用函数式编程范型。
面向对象编程核心
OO三大特性
对象是现实世界的模型。面向对象编程的三个基本要素是封装、继承和多态。 封装即利用抽象数据类型将数据和对数据的操作包装在一起,使其构成一个不可分割的独立体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。系统的其他对象只能通过包裹在数据外面的已经授权的操作来与这个封装的对象进行交流和交互。也就是说用户是无需知道对象内部的细节,但可以通过该对象对外提供的接口来访问该对象。 继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以使用用父类的属性和功能。通过使用继承我们能够非常方便地复用以前的代码,提高开发效率。 所谓多态是指向在继承中,子类重写了父类的方法,而父类数据类型的引用指向子类的对象(向上转型),使得父类数据类型的引用可以用统一的代码实现不同的逻辑,表现出不同的行为。
OO设计原则(7个)
除了高内聚、低耦合、关注点分离、模块化开发等软件设计的一些通用原则外,面向对象编程一般还遵循7个重要的原则。即SOLID原则(单一职责原则、开放封闭原则、里氏替换原则、依赖导致原则、接口分离原则),最少知识原则(迪米特法则)和合成复用原则。
单一职责原则(Single Responsibility Principle)
一个对象应该只包含单一定职责,并且该职责被完整地封装在一个类中。
开闭原则(Open Closed Principle)
一个软件实体应当对扩展开放,对修改关闭,也就是说在设计一个模块或类的时候,应当使这个模块可以在不被修改的前提下被扩展,即实现在不修改源代码的情况下改变这个模块的行为。
里氏代换原则(Liskov Substitution Principle)
所有引用基类的地方必须能够透明地使用其子类地对象。也就是继承必须确保基类所拥有的性质在子类中仍然成立。LSP是继承复用的基石,只有当衍生类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。
依赖倒转原则(Dependency Inversion Principle)
依赖接口编程,不要依赖具体类的实现编程。
接口隔离原则(Interface Segregation Principle)
客户端不应该依赖那些它不需要地接口。使用多个专门的客户端接口比使用单一的宽泛用途的接口要好。如果强迫用户使用它们不使用的方法,那么这些客户就会面临由于这些不使用的方法的改变所带来的改变。
迪米特法则(Law of Demeter)
也叫最少知识原则(Least Knowledge Principle),每一个模块对其他的模块都只有最少的知识,而且局限于那些与本模块密切相关的软件模块。对象与对象之间应该使用尽可能少的方法来关联,避免千丝万缕的关系。在类的划分上,应当创建有弱耦合的类,类之间的耦合越弱,就越有利于复用。在类的结构设计上,每一个类都应当尽量降低成员的访问权限。在对其它对象的引用上,一个类对其它对象的引用应该降到最低。
组合复用原则(Composite Reuse Principle)
尽量使用对象组合(Has-A),而不是继承(Is-A)来达到复用的目的。因为组合这种复用是黑箱复用,成员对象的内部细节是新对象所看不见的。这种复用也可以在运行时间动态进行,新对象可以动态的引用与成员对象类型相同的对象,将职责委托给具有相同超类型的对象。 而继承复用中从超类继承而来的实现是静态的,不可能在运行时间内发生改变,没有足够的灵活性。
OO设计模式(23个)
在编程中,设计模式的引入可以获得遵循上文所述的设计原则的软件架构,而代价是增加了代码的复杂度。 就像信耶稣的人都要读圣经,信OO的人都要读四人组(GOF)的《设计模式》。GOF根据设计模式的目标将模式分为三类:创建型、结构型和行为型。
创建型模式
创建型模式设计对象的实例化,这类模式的特点是,不让用户依赖于对象的创建方式,避免用户直接使用new运算符创建对象。
GOF的23中模式中的下列5种模式属于创建型模式:
- 工厂方法模式:定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
- 抽象工厂模式:提供一个创建一系列或相互依赖对象的接口,而不需要明确指定具体类。
- 建造者/生成器模式(Builder Pattern):
封装一个产品的构造过程,并允许按步骤构造。将一个复杂对象的创建过程封装起来,向客户隐藏了产品内部的表现。允许对象通过多个步骤来创建,并且可以改变过程(这个只有一个步骤的工厂模式不同)。产品的实现可以被替换,因为客户只能看到一个抽象的接口。建造者模式包含如下角色:
Builder(抽象建造者)
ConcreteBuilder(具体建造者)
Director(指挥者)
Product(产品角色)。
类图如下:
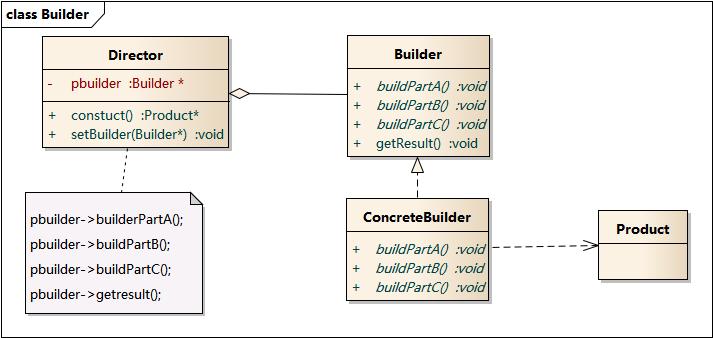
其中,Builder角色有提供很多部件的能力,对应到代码就是Builder类有很多创建方法。Director角色对材料进行按需生产和组装,他能把复杂的Product创建过程对外隐藏,使Builder部件和创建过程分离,各方易于扩展,降低了耦合度。这些角色联合起来用于构建一个复杂的Product对象,如下所示:
Builder * builder = new ConcreteBuilder();
Director * director = new Director();
director.setBuilder(builder);
Product * product = director.construct(); //通过多个步骤来创建Product
在我们的日常开发中,往往需要对一个对象,设置很多属性,此时也可以方便的使用下文的链式调用来提高编码速度和代码可读性。
结构型模式
结构型模式涉及如何组合类和对象以形成更大的结构,和类有关的结构型模式设计如何合理地使用继承机制;和对象有关的结构型模式涉及如何合理地使用对象组合机制。
GOF的23种模式中的下列7种模式属于创建型模式:
- 适配器模式:将一个类的接口转换成客户希望的另外一个接口。Adapter模式使原本由于接口不兼容而不能一起工作的那些类可以一起工作。
-
组合模式:将对象组合成树形结构以表示”部分-整体“的层次结构。Composite模式使用户对单个对象和组合对象的使用具有一致性。组合模式可以应用于GUI中的父子组件、文件夹和文件的嵌套关系的抽象。
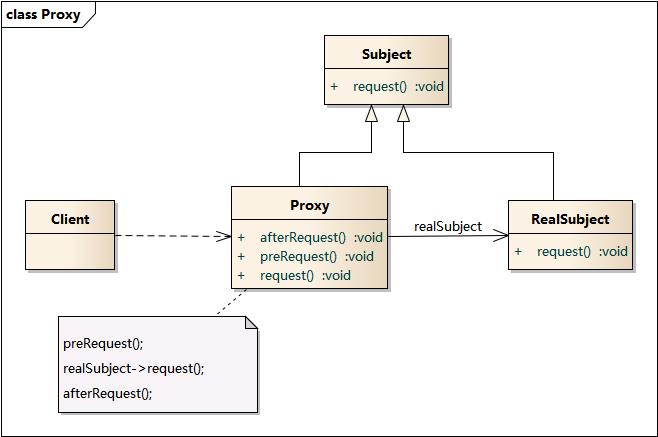
- 代理模式:为其他对象提供一种代理以控制对这个对象的访问。代理模式包含如下角色:Subject(抽象主题角色), Proxy(代理主题角色), RealSubject(真实主题角色)。类图如下:
- 享元模式:运用共享技术有效地支持大量细粒度的对象, 一般用来解决内存占用高等性能问题。
- 外观模式:为系统的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使这一子系统更加容易使用。
-
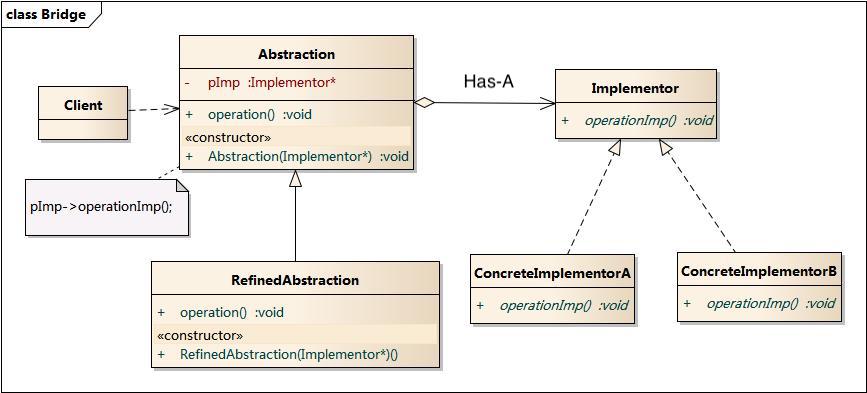
桥接模式:将抽象部分与它的实现部分分离,使它们都可以独立地变化。Bridge模式通过将实现和抽象放在两个不同的类层次中而使它们可以独立改变。桥接模式适用情况包括:需要在构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的继承联系;抽象化角色和实现化角色可以以继承的方式独立扩展而互不影响;一个类存在两个独立变化的维度,且这两个维度都需要进行扩展;设计要求需要独立管理抽象化角色和具体化角色;不希望使用继承或因为多层次继承导致系统中类的个数急剧增加。桥接模式包含如下角色: Abstraction(抽象类) RefinedAbstraction(扩充的抽象类) Implementor(实现类接口) ConcreteImplementor(具体实现类)。 类图如下:
- 装饰者模式:以对客户透明的方式动态地给一个对象附加上更多的责任,客户端并不会觉得对象在装饰前和装饰后有什么不同。装饰模式可以在不需要创造更多子类的情况下,通过在对象中嵌入其他类(我们称这个嵌入的对象为装饰器)的成员属性的方式将对象的功能加以扩展。
行为型模式
行为模式涉及怎样合理地设计对象之间的交互通信,以及怎样合理为对象分配职责,让设计富有弹性,易维护和易复用。
GOF的23种模式中的下列11种模式属于创建型模式:
-
观察者模式:定义对象间的一种一对多的依赖关系,当一个对象的状态发生变化时,所有依赖于它的对象都得到通知并被自动更新。
-
迭代器模式:提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。
-
状态模式:允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。
-
中介者模式:用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显示地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
-
命令模式:将一个请求封装为一个对象,从而可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。
-
策略模式:定义一系列算法,把它们一个个封装起来,并且可使它们可以相互替换。策略模式使算法可独立于使用它的客户而变化。
-
责任链模式:又名职责链模式,它使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
-
解释器模式:给定一个语言,定义它文法的一种表示,并定义一个解释器,解释器会将每个语法规则表示成一个类,这个解释器使用该表示来解释给定语言中的语句。
- 备忘录模式:在不破坏封装性的情况下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样以后就可将该对象恢复到原先保存的状态。Memento模式在前端JS中经常用于数据缓存. 比如一个分页控件, 从服务器获得某一页的数据后可以存入缓存。以后再翻回这一页的时候,可以直接使用缓存里的数据而无需再次请求服务器。
实现比较简单,伪代码:
var Page = function(){ var page = 1, cache = {}, data; return function( page ){ if ( cache[ page ] ){ data = cache[ page ]; render( data ); }else{ Ajax.send( 'api.xx.com/xxx', function( data ){ cache[ page ] = data; render( data ); }) } } }() -
模板方法模式:定义一个操作中算法的骨架,而将一些步骤延迟到子类中。模板方法使子类可以不改变一个算法的结构即可定义该算法的某些特定步骤。
- 访问者模式:访问者模式在GOF的23中设计模式中可能是比较难于理解的一个,它表示一个作用于某个结构对象集合中的各元素的操作。它可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
我们在使用一些操作对不同的对象进行处理时,往往会根据不同的对象选择不同的处理方法和过程。在实际的代码过程中,我们可以发现,如果让所有的操作分散到各个对象中,整个系统会变得 难以维护和修改。且增加新的操作通常都要修改所有的类。 因此,为了解决这个问题,我们可以将每一个类中的相关操作提取出来,包装成一个独立的对象,这个对象我们就称为访问者(Visitor)。利用访问者,对访问的元素进行某些操作时,只需将此对象作为参数传递给当前访问者,然后,访问者会依据被访问者的具体信息,进行相关的操作。
一般来说其中包含五个角色, Abstract Visitor(抽象访问者):声明访问者可以访问哪些元素,具体到程序中就是visit方法中的参数定义哪些对象是可以被访问的。 Visitor(访问者):实现抽象访问者所声明的方法,它影响到访问者访问到一个元素类后要做什么事情。 Abstract Element(抽象元素类):声明接受哪一类访问者访问,程序上是通过accept方法中的参数来定义的。抽象元素一般有两类方法,一部分是本身的业务逻辑,另外就是允许接收哪类访问者来访问。 Element(元素类):实现抽象元素类所声明的accept方法,通常都是visitor.visit(this),基本上已经形成一种定式了。 Structure Object(结构对象):一个元素的容器,一般包含一个容纳多个不同类、不同接口的容器,如List、Set、Map等。这个角色在项目中通常是可选的。
在JavaScript这类弱类型语言中,很多方法里都不做对象的类型检测,而是只关心这些对象能做什么。因此我们不需要作为接口描述的两个抽象角色,其代码实现如下:
// 访问者
function Visitor() {
this.visit = function( concreteElement ) {
concreteElement.doSomething();
}
}
// 元素类
function ConceteElement() {
this.doSomething = function() {
console.log("这是一个具体元素");
}
this.accept = function( visitor ) {
visitor.visit(this);
}
}
// Client
var ele = new ConceteElement();
var v = new Visitor();
ele.accept( v );
其实,在js这种基于鸭子类型的语言中,访问者模式几乎是原生的实现, 所以我们可以利用apply和call毫不费力的使用访问者模式。Array构造器的prototype上的方法就被特意设计成了访问者,这些方法不对this的数据类型做任何校验。例如给一个Object对象增加push,pop方法,我们可以这样实现:
function Visitor() {
this.push = function(ele, ...args) { //visit function
return Array.prototype.push.apply(ele, args);
}
this.pop = function() {
return Array.prototype.pop.apply(ele);
}
};
let v = new Visitor();
let ele = {};
v.push(ele, 1, 2, 3, 4);
console.log(ele); // { '0': 1, '1': 2, '2': 3, '3': 4, length: 4 }
ele.pop();
console.log(ele); //{ '0': 1, '1': 2, '2':3, length: 3 }
戴着模式的眼镜再看MVC架构
MVC是GUI的开发中经常采用的一种的一种架构,MVC即模型-视图-控制器。其中,模型包含业务数据,当模型变化,会通知它的观察者。视图即用户界面,它观察模型并展示其模型的当前状态;每个视图有一个对应的控制器;视图可以有它的子视图。控制器管理逻辑和用户输入,决定当用户和视图交互时做什么。
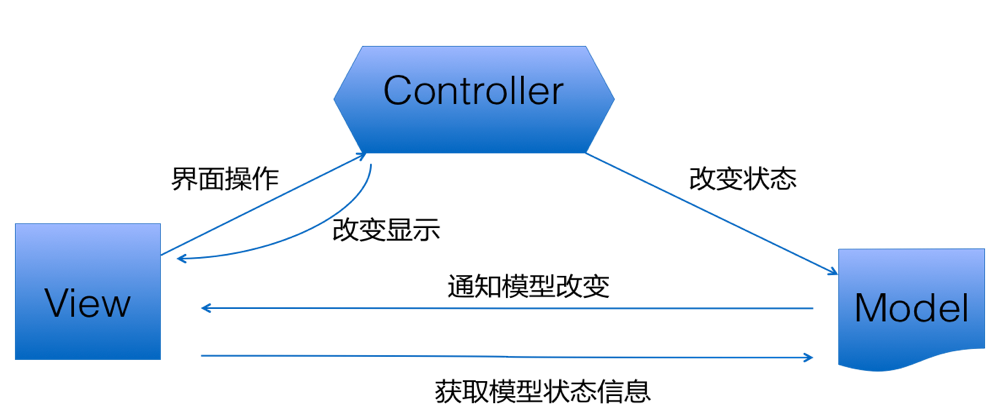
从模式的角度来看MVC架构,我们发现它是复合模式,结合了观察者模式,策略模式和组合模式。模型使用观察者模式,以便观察者更新,同时保持两者之前解耦。控制器是视图的策略,视图可以使用不同的控制器实现,得到不同的行为。视图使用组合模式实现用户界面,用户界面通常组合了嵌套的组件。这些模式携手合作,把MVC模型的三层解耦,这样可以保持设计干净又有弹性。
函数式编程核心
函数式编程是阿隆佐·邱奇(Alonzo Church)思想的在现实世界中的实现。Lambda演算在最初设计的时候就是为了研究计算相关的问题。所以函数式编程主要解决的也是计算问题。窃以为函数式编程的核心特性是数据的不可变性(Immutability)和高阶函数(High Order Function),下面分别解释。
不可变的数据(Immutable Data)
数据的不变性包括两层含义:
- 没有变量,只有常量,任何一个“变量”一旦被赋值,就不能再次被赋值。类似于所以的变量都是用final(in Java)或const(in C/C++/JS/etc)修饰过了的。
- 没有可变的数据结构,数据一旦被创建出来,就不能被修改了。比如一个数组被创建出来以后,就不能再增、删、改里面的元素了;一个Map(Hash、Dictionary)被创建出来以后,里面的key-value对儿也是不能再变的的,也不能add key,也不能remove key,一个对象/Struct一旦被创建,里面的每一个field都不能被改变。
不可预测的变量vs可预测的常量
看看以下代码:
let age = 18;
happy_new_year();
console.log(age);
上面这段小代码,对于非FP来说,age是可以变的,所以你必须去看happy_new_year里面的代码,才知道age最后到底是什么样的值。而对于FP来说,你不用去管happy_new_year()里面的代码是什么样的,你就能确定age的值一定是18。因为变量age一旦被赋值,就不会被改变了。相当于所有变量都是const的常量。 从这个简单的例子就可以看出,FP可以极大的提高代码的可读性(可预测性),降低认知负担。
可变的数据结构vs不可变的数据结构
如果我们在代码中允许修改一个对象的属性,示例如下:
const staff1 = {
company: "Kingsoft",
name: 'Marlon',
birthdate: '1986-09-01',
};
const changeStaff = (staff, newName, newBday) => {
const newStaff = staff;
newStaff.name = newName;
newStaff.birthdate = newBday;
return newStaff;
};
const staff2 = changeStaff(staff1, 'Kevin', '1996-11-10');
console.log(staff1, staff2); //两个对象有相同的属性值
我们发现,尽管创建了一个新的对象staff2,但是老的对象staff1也被改动了。这是因为JS对象中的赋值是“引用赋值”。为了避免修改数据,引入函数副作用,我们需要改写changeStaff函数为一个纯函数(pure functions),保证数据的不可变性,代码如下所示:
const changeStaff = (staff, newName, newBday) => {
//Object.assign() 方法将所有可枚举属性的值从一个或多个源对象复制到目标对象
return Object.assign({}, staff, {name: newName, birthdate: newBday});
};
const staff2 = changeStaff(staff1, 'Kevin', '1996-11-10');
console.log(staff1, staff2); //{ company: 'Kingsoft', name: 'Marlon', birthdate: '1986-09-01' } { company: 'Kingsoft', name: 'Kevin', birthdate: '1996-11-10' }
这一实现不会直接修改staff1对象的属性,而是重新创建了一个新的对象并拷贝原始对象。需要注意的是Object.assign方法实行的是浅拷贝,而不是深拷贝。也就是说,如果源对象某个属性的值是对象,那么目标对象拷贝得到的是这个属性对象的引用。在这种情况下,手动递归实现深拷贝会存在性能上的问题,所以一般采用immutable.js类库来处理不可变数据。其实现既保证了不可变性,又保证了性能大限度优化。
数据的不可变性并不是不改变值。它是指在程序状态改变时,不直接修改当前数据,而是创建并追踪一个新数据。这使得我们在读代码时更有信心,因为我们限制了状态改变的场景,状态不会在意料之外或不易观察的地方发生改变。
高阶函数(High Order Function)
高阶函数是指至少满足下列条件之一的函数:
- 函数可以作为参数被传递
- 函数可以作为返回值输出
高阶函数使得在FP中的函数成为像Number或是String这样的第一类对象,它和Java中操作其他类(也就是把一个类实例传给另外的类)的类没有什么区别。
函数作为参数被传递的例子可以在单例模式中找到,代码如下:
var getSingleton = function ( fn ) {
var ret; //闭包环境中的私有变量
return function () {
return ret || (ret = fn.apply(this, arguments));
};
};
其中getSingleton函数的参数一般是一个用于创建对象的函数。
函数作为返回值输出的例子也可以在 装饰者模式中看到,相关代码如下:
Function.prototype.before = function( beforefn ) {
var __self = this;
return function() {
beforefn.apply(this, arguments );//先执行传入的装饰函数
return __self.apply( this, arguments );//执行原函数
}
}
这段代码扩展Function.的原型,增加before函数,该函数返回一个把一个传入的函数“动态织入”原始函数前的函数。
闭包(Closure)
闭包是词法闭包(Lexical Closure)的简称,它是由一个高阶函数和与其相关的引用环境(词法作用域)组合而成的实体。 闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。所谓引用环境是指在程序执行中的某个点所有处于活跃状态的变量所组成的集合。 闭包提供了一个在返回函数的外层作用域结束后仍然能访问该作用域中变量的机制。让我们来看一个例子:
function make_counter() {
let count = 0;
function inc_count() {
count++;
return count;
}
return inc_count;
}
let c1 = make_counter();
let c2 = make_counter();
console.log(c1()); //1
console.log(c2()); //1
console.log(c1()); //2
在这段程序中,函数 inc_count 定义在函数 make_counter 内部,并作为 make_counter 的返回值。变量 count 不是 inc_count 内的局部变量,按照最内嵌套作用域的规则,inc_count 中的 count 引用的是外层函数中的局部变量 count。接下来的代码中两次调用 make_counter() ,并把返回值分别赋值给 c1 和 c2 ,然后又依次打印调用 c1,c2 和c1 所得到的返回值。 这里存在一个问题,当调用 make_counter 时,在其执行上下文中生成了局部变量 count 的实例,所以函数 inc_count 中的 count 引用的就是这个实例。 但是 inc_count 函数并没有在此时被执行,而是作为返回值返回。当 make_counter 返回后,其执行上下文将失效,count 实例的生命周期也就结束了,在后面对 c1 和 c2 调用实际是对 inc_count 的调用,此时 count 所在的引用环境(词法作用域)已经销毁,这看起来是无法正确执行的。
在JavaScript这样的函数语言中,如果按照作用域规则在执行时确定一个函数的引用环境,那么这个引用环境可能和函数定义时不同。 要想使这段程序正常执行,一个简单的办法是在函数定义时捕获当时的引用环境,并与函数代码组合成一个整体。当把这个整体当作函数调用时,先把其中的引用环境覆盖到当前的引用环境上,然后执行具体代码,并在调用结束后恢复原来的引用环境。这样就保证了函数定义和执行时的引用环境是相同的。这种由引用环境与函数代码组成的实体就是闭包。 所以闭包不是函数,只有引用环境在函数的定义和执行时可能发生变化的函数,才需要将其转化为闭包。
在上述例子中,c1 和 c2 是 make_counter 高阶函数的两个闭包运行实例,依次调用 c1, c2, c1 时,分别改变了这两个引用环境中的变量 counte 的值, 因此分别输出1, 1, 2。
闭包是数据和行为的组合,这使得闭包具有较好抽象能力,可以通过闭包来模拟面向对象编程。借用Python社区一个非常好的说法来做个总结:对象是附有行为的数据,而闭包是附有数据的行为。
FP设计模式
Lambda表达式
Lambda表达式(也称箭头函数)是定义函数最简洁的方法,是将匿名函数复制给变量的简写方式的函数。这一功能在许多现代语言的编译器中都有实现,在JavaScript的ES6中,Lambda表达式的定义如下,符号的左侧是参数,右侧是表达式或语句块。
(参数列表) => { 语句块 }
//当“语句块”只有一条语句的时候,可以省略大括号,如下
(参数列表) => 语句
例如计算两个数的和的函数可以用如下Lambda表达式实现:
var sum = (x,y)=>x+y;
在Python中Lambda表达式也用来定义一个匿名函数,如:
increase = lambda x:x+1
increase(1) # output: 2
在Java8中也提供了这种“函数式编程”的方法,供我们来更加简明扼要的实现内部匿名类的功能。 定义一个接口,接口里面必须有且只有一个抽象方法 ,这样的接口就成为函数式接口(Functional Interface)。在Java8及以上的程序中,函数式接口都可以尽量使用Lambda表达式来实现,如下所示:
public class WorkerInterfaceTest {
public static void execute(WorkerInterface worker) {
worker.doSomeWork();
}
public static void main(String [] args) {
//invoke doSomeWork using Lambda expression
execute( () -> System.out.println("Worker invoked using Lambda expression") );
}
}
C++11也引入了Lambda表达式,利用Lambda表达式可以编写内嵌的匿名函数,用以替换独立函数或者函数对象(在类中,可以重载函数调用运算符(),此时类的对象可以将具有类似函数的行为,称为函数对象),并且使代码更可读。 如下所示:
#include <iostream>
using namespace std;
int main() {
// 定义简单的lambda表达式 (auto关键字对变量进行类型推导)
auto basicLambda = [] { cout << "Hello, world!" << endl; };
// 调用
basicLambda(); // 输出:Hello, world!
}
在C++中,每当你定义一个lambda表达式后,编译器会自动生成一个匿名类(这个类重载了()运算符),我们称为闭包类型(closure type)。那么在运行时,这个lambda表达式就会返回一个匿名的闭包实例。闭包的一个强大之处是其可以通过传值或者引用的方式捕捉其封装作用域内的变量,lambda表达式最前面的方括号就是用来定义捕捉模式以及变量,我们又将其称为lambda捕捉块。当lambda捕捉块为空时,表示没有捕捉任何变量。
可迭代对象的函数式操作/列表处理
列表(或其他可迭代对象)的处理操作在非函数式编程的上下文中一般采用for循环迭代,或forEach来遍历列表,对其中的每个元素进行处理。这类方法可能在处理中修改列表中的元素,是有副作用的。 而支持函数式编程风格的语言一般支持三种无副作用的列表处理操作map,filter和reduce。map函数的作用是将列表中的每个元素的值映射到另一个值;filter函数是一个过滤器,删除列表中所有不满足条件的元素;而reduce函数将列表中的值合并(或减少)到单个值。
有一个用emoji来生动地说明这三个函数作用的图片,如下所示:
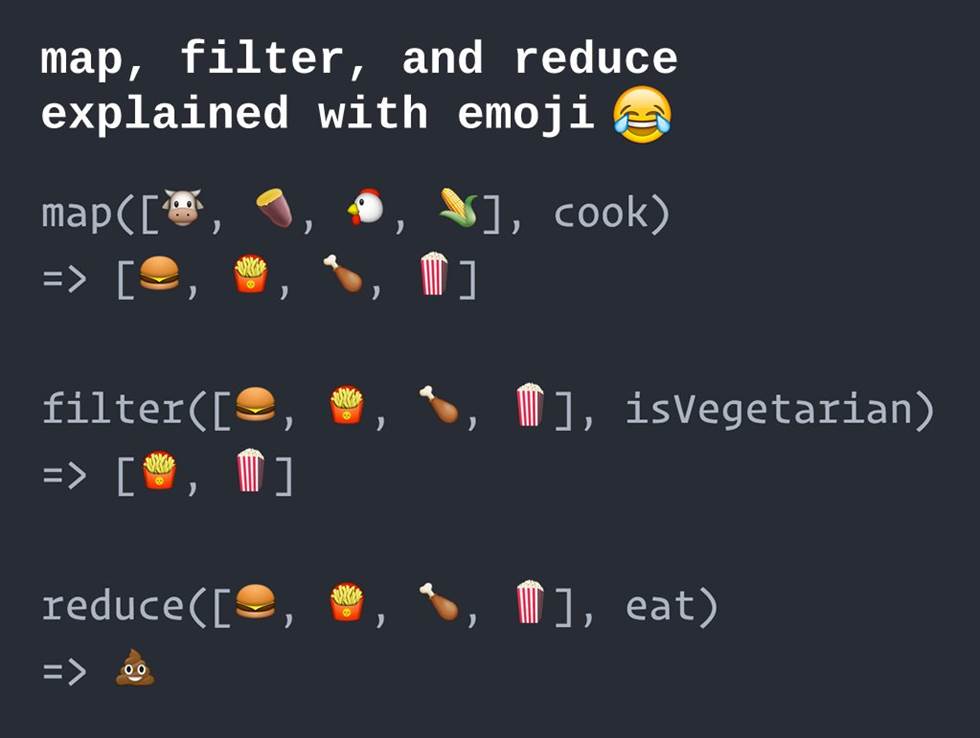
牛、红薯、鸡、玉米烹调映射为汉堡包、薯条、炸鸡腿和爆米花四种食物,这四种食物通过素食条件的过滤,得到薯条和爆米花。而将四种食物一起吃下,便产出了💩。
在不同语言中,map,filter和reduce三个函数的名字有些许变化,可以在下表看到JavaScript、Python以及C++中这三个函数的名称的比较。
| JavaScript | C++ | Python |
|---|---|---|
| map | std:transform | map |
| filter | std:remove_if | filter |
| reduce | std:accumulate | reduce |
让我们来看一个应用的例子, 首先初始化一个字符串列表,内容为包含”Programming”,”in”,”a”,”functional”,”style.” 5个单词的一句话。通过map函数求每个单词的长度,通过filter函数获得首字母为大写的单词,通过reduce函数将所有字符串连接起来(用冒号分隔)。
JavaScript实现如下:
const str = ["Programming", "in", "a", "functional", "style."];
//map
const lengths = str.map(word => {
return word.length;
});
console.log(lengths); //[11, 2, 1, 10, 6]
//filter
const filtered = str.filter(word => {
return word[0] == word[0].toUpperCase();
});
console.log(filtered); // [ 'Programming' ]
//reduce
const jointStr = str.reduce((acc, cur) => {
return acc + ':' + cur;
}, '');
console.log(jointStr); // :Programming:in:a:functional:style.
Python实现如下:
str = ["Programming", "in", "a", "functional", "style."]
# map
lengths = map(lambda word : len(word), str)
# filter
filtered = filter(lambda word: word[0].isupper(), str)
# reduce
jointStr = reduce(lambda acc, cur: acc + ":" + cur, str, "")
C++实现如下:
#include <iostream>
#include <vector>
#include <algorithm> //std::remove_if
#include <numeric> // std::accumulate
using namespace std;
int main() {
vector<string> str = {"Programming", "in", "a", "functional", "style."};
vector<int> vout; //输出列表
//map
transform(str.begin(), str.end(), back_inserter(vout), [](string s){ return s.length ();} );
for(auto val : vout) {
cout<< val << endl;
}
//filter
//remove_if only guarantees that [begin, middle) contains the matching elements
vector<string>::iterator endfilter = remove_if(str.begin(), str.end(), [](string s) {return !(isupper(s[0]));} );
for(auto it = str.begin(); it != endfilter; ++it) {
cout<< *it << endl;
}
//reduce
string jointStr = accumulate(str.begin(), str.end(), string(""), [](string first, string second){ return first + ":" + second; });
cout<< jointStr << endl;
}
链式调用
在函数式编程中链式方法调用是一种很常见的模式,例如在JavaScript的jQuery中,你会经常使用这种方法。如:
$('#div1').children('span').hide();
这是一种在一个对象上一个接一个的应用多个函数的简化的写法,这样写无论在可读性和代码量上都有优势。 链式调用也常常和创建者模式(Builder Pattern)一起使用。在创建者模式中,Builder角色会有很多构建对象的方法,可以通过每个方法return this,来进行链式的调用。即:
//具体构建者
// ConcreteBuilder.cpp
#include "ConcreteBuilder.h"
//...
ConcreteBuilder* ConcreteBuilder::buildPartA(){
//...创建需要的内容
return this;
}
ConcreteBuilder* ConcreteBuilder::buildPartB(){
//...
return this;
}
ConcreteBuilder* ConcreteBuilder::buildPartC(){
//...
return this;
}
//指挥者
// Director.cpp
#include "Director.h"
//...
Product* Director::constuct(){
//链式调用的组装过程
return pbuilder->buildPartA()->buildPartB()->buildPartC()->getResult();
}
void Director::setBuilder(Builder* buider){
pbuilder = buider;
}
在具体构建者中,相关的成员函数返回this对象,以便指挥者类中可以通过代表构建者的pbuilder成员变量来链式的调用相关成员函数,来构建组装产品。
部分应用(Partial Application)
在JavaScript中,闭包结构可以用于创建一个有用的设计模式,被称为部分应用(在纯粹的函数式语言中,一般不说函数是被调用的,而说函数是被应用的)或函数工厂(function factories)。部分应用允许我们手动绑定一个或多个预设的实参到一个通用的函数,该函数返回一个部分应用于预设参数的更具体的函数,它可以接收剩下的参数完成函数的应用。
function bindFirstArg(func, first) {
return function(second) {
return func(first, second);
}
}
function bindSecondArg(func, second) {
return function(first) {
return func(first, second);
}
}
let powerOfTwo = bindFirstArg(Math.pow, 2);
console.log(powerOfTwo(5)); //32
let squareOf = bindSecondArg(Math.pow, 2);
console.log(squareOf(3)); // 9
let cubeOf = bindSecondArg(Math.pow, 3);
console.log(cubeOf(3)); // 27
let makePowersOf = bindFirstArg(bindFirstArg, Math.pow);
let powerOfThree = makePowersOf(3);
console.log(powerOfThree(2)); // 9
在这个示例中,bindFirstArg函数接收两个参数,第一个参数是一个函数func,第二个参数是func函数的第一个参数,然后它返回一个将参数作为传入函数func的第二个参数的函数。 通过bindFirstArg函数我们可以将指数函数和它的第一个参数绑定在一起,获得一个具体的指数函数(如powerOfTwo)。 如果我们将bindFirstArg函数作为第一个参数传递给它自己,我们便能创建一个可绑定的通用的函数,如上例中的指数函数 makePowersOf,这也是为什么部分应用也被称为函数工厂的原因。
再让我们来看一个部分应用的例子,它不仅适用于正好有两个参数的函数,也可以适用于具有不同参数的函数。
Function.prototype.partialApply = function() {
let func = this;
let args = Array.prototype.slice.call(arguments);
return function() {
let newArgs = [].slice.call(arguments);
return func.apply(this, args.concat(newArgs));
}
}
let greet = function(greeting, name, punctuation) {
return greeting + ' ' + name + ' ' + punctuation;
};
let sayHelloTo = greet.partialApply('hello');
console.log(sayHelloTo('Marlon', ': )')); //hello Marlon : )
let sayHelloToKevin = greet.partialApply('hello', 'Kevin');
console.log(sayHelloToKevin('!')); // hello Kevin !
在该例子中,首先在Function对象的原型上定义了一个partialApplay方法,它返回一个部分应用了给定参数的函数,该函数将预设参数和该函数的参数连接起来,再全部应用到当前函数上。 greet 函数是一个返回寒暄语句的函数,sayHelloTo 是 greet 通过部分应用了 hello 参数的函数,后续只需要传入其余参数调用 sayHelloTo 函数便可完成任务。而 sayHelloToKevin 函数是 greet 通过部分应用了 hello 和 Kevin 两个实参的函数。
能够创建一个通用的函数在函数式编程中是一个重要的能力。部分应用允许我们定义通用的函数工厂,并从这个通用的函数中扩展出更具体的函数。
局部套用(currying)
局部套用又称为柯里化(currying), 和部分应用相似,局部套用也可以分步骤的将函数应用于多个参数;不同的是部分应用会也可能不会有可预期的返回类型,而局部套用函数 始终返回一个具有单个参数的函数,即柯里化是输入一个有多个参数的函数,返回一个只接收单个参数的函数。请看如下示例:
Function.prototype.curry = function(numArgs) {
let func = this;
numArgs = numArgs || func.length;
//recursively acquire the arguments
function subCurry(prev) {
return function(arg) {
let args = prev.concat(arg);
if (args.length < numArgs) {
return subCurry(args);
} else {
// base case: apply the function
return func.apply(this, args);
}
}
}
return subCurry([]);
}
let greet = function(greeting, name, punctuation) {
return greeting + ' ' + name + ' ' + punctuation;
};
let sayHelloTo = greet.curry();
console.log(sayHelloTo('hello')); //returns a curried function
console.log(sayHelloTo('hello')('Marlon')(': )')); // hello Marlon : )
在Function对象原型上的curry函数中,numArgs参数允许我们指定被柯里化函数的参数数目。柯里化函数通过递归的方式每次应用一个参数,返回一个只具有一个参数的函数。 只要应用的部分参数的数目小于原函数需要的参数数目,则返回一个柯里化的函数,否则原函数完成对所有参数的应用返回最终结果。
局部套用可以提升原来的函数,它用标准化的方式处理所有的参数,返回相同函数类型的接口,返回的函数必定是一元的。这种提升方式不仅是为了创建函数工厂和代码重用,也使得函数组合更加容易实现。
函数组合(function composition)
函数组合将一个函数的返回值传给另一个函数作为参数。由于一个函数只能返回一个值,所以接收返回值作为参数的函数必定是一元的(Unary),例如c(x)=f(g(x))。
Function.prototype.compose = function(prevFunc) {
let nextFunc = this;
return function() {
return nextFunc.call(this, prevFunc.apply(this, arguments));
}
}
function func1(a) {
return a + ' 1';
}
function func2(b) {
return b + ' 2';
}
function func3(c) {
return c + ' 3';
}
let composition = func3.compose(func2).compose(func1);
console.log(composition('count'));
我们在Function对象上增加compose函数,它将参数函数和当前调用compose的函数组合起来应用。 函数组合将所有方法转换为一元的纯函数,鼓励使用更简单,更小的函数来完成单一的任务,有利于模块化开发。
尾递归代替循环
递归本质上是一种循环操作。纯粹的函数式编程语言没有循环操作命令,所有的循环都用递归实现,这就是为什么尾递归对这些语言极其重要。对于其他支持”尾调用优化”的语言(比如Lua,ES6), 循环可以用递归代替,而一旦使用递归,就最好使用尾递归。以防止出现了调用栈溢出的异常。
递归算法的典型代表是斐波那契数列,普通的递归实现如下:
function fib(n) {
if (n <= 1){
return n;
} else {
return fib(n-1) + fib(n - 2);
}
}
console.log(fib(5))
/*
fib(5)
/ \
/ \
fib(4) fib(3)
/ \ / \
/ \ / \
fib(3) fib(2) .........
/ \ / \
/ \ / \
fib(2) fib(1) fib(1) fib(0)
/ \
/ \
fib(1) fib(0)
*/
上面的树状图展示了fib(5)的递归调用过程,每个节点代表依次对fib函数的调用。
我们知道,函数调用会在内存形成一个”调用记录”,保存引用环境中的局部变量(上下文),又称”调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用记录上方,还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失。 如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,就形成一个”调用栈”(call stack)。 在上例中,fib(5)函数调用的调用栈状态如下所示:
[ 'fib(5)',
'fib(4)',
'fib(3)','fib(2)','fib(1)','fib(0)','fib(1)',
'fib(2)','fib(1)','fib(0)',
'fib(3)','fib(2)','fib(1)','fib(0)','fib(1)' ]
如上所示,在递归调用过程中,调用栈中先后压入了15个调用帧用于保存当时的函数引用环境。这种递归算法有一个问题,就是在输入较大时(如计算fib(2345)),会导致调用栈溢出(Maximum call stack exceeded),普通的递归函数非常耗费内存,因为需要同时保存成千上万个调用记录,很容易发生栈溢出错误。一般根据执行引擎不同在调用栈上万时可能会发生这个问题,而尾递归调用可以解决调用栈溢出的问题。
尾递归即在函数的最后一步操作来调用自身,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了。只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了。它在递归调用时只保留一个调用记录,内存的空间复杂度为O(1) 。上述斐波那契数列的计算改写成尾递归的实现,代码如下:
"use strict";
let bigInt = require("big-integer");
function fibIterRecursive(n, a, b){
if (n === 0) {
return b;
} else {
return fibIterRecursive(n-1, bigInt(a).add(bigInt(b)), bigInt(a));
}
};
function fib2(n){
return fibIterRecursive(n, 1, 0);
}
console.log(fib2(2345).toString())
其中bigInt是封装任意精度的整数运算的库,在某些浏览器中也有原生实现。ES6的尾调用优化只在严格模式下开启,正常模式是无效的。另外目前只有Safari浏览器部署了尾递归调用, V8引擎实际上已经实现了尾调用优化,但是默认是关闭该功能的。因此在Node.js中需要通过 –harmony_tailcalls 参数来开启尾递归优化。而gcc可以使用-O2参数开启尾递归优化。 pyhon中可以通过一个 tail_call_optimized 装饰器,模拟尾递归优化。
惰性求值
惰性求值(Lazy Evaluation),也称为传需求调用(call-by-need)和延迟执行(deffered execution),是在需要时才进行求值的计算方式。 在函数式编程中,它表示一种仅当一个函数的返回值被明确的使用时,才执行函数。或者表达式不在它被绑定到变量之后就立即求值,而是在该值被取用的时候求值。它的目的是要最小化计算工作(最小化求值),可以提升程序的性能。另一方面,惰性求值可以优化迭代操作,它不要求你事先准备好整个迭代过程中所有的元素,仅仅在迭代至某个元素时才计算该元素,使得构造一个无限的数据结构成为可能。
在JavaScript中, 表达式是立即求值的,所以想要惰性求值需要将求值的过程包装为函数,只在需要求值的时候才调用该函数。如下所示:
let value1 = 2018;
let value2 = () => 2019; //箭头函数
console.log(value2);
console.log(value2());
Lazy.js是一个函数式编程的惰性求值库,其使用的示例代码如下:
let Lazy = require('lazy.js');
function square(x) { return x * x; }
function isEven(x) { return x % 2 === 0; }
let array = Lazy.range(1000).toArray(); //0...999
let result = Lazy(array).map(square).filter(isEven).first(5); //收集计算需求,延迟计算的执行
result.each((e) => { //直到你调用了each或toArray等操作才会产生迭代,而且不会创建中间数组
console.log(e);
});
如上所示,lazy.js通过使用前文所述的链式调用,达成了良好的代码可读性,并通过惰性求值实现了良好的代码执行效率。具体的,这里首先创建一个包含1000个整数的数组,注意我们调用了toArray。如果没有这个,Lazy.range给我们的将不是一个数组而是一个Lazy.Sequence对象,你可以通过each来迭代这个对象。然后取每个数字的平方,再取出前5个偶数,最后迭代result并输出元素。这里的惰性求值可以基于Generator函数实现(生成器是一个返回迭代器对象的函数,可用于迭代操作)。
在Python中,我们同样也可以通过生成器来实现延迟计算,如下所示:
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 1, 1, 0
while True:
if (counter > n):
return
yield a # yield 语句
a, b = b, a + b
counter += 1
iterator = fibonacci(10) # f 是一个迭代器,由生成器返回生成
for i in iterator:
print(i, end=" ") # 1 1 2 3 5 8 13 21 34 55 89
在 Python 中,使用了 yield 的函数被称为生成器(generator)。在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。调用一个生成器函数,返回的是一个迭代器对象。上例中使用 yield 实现斐波那契数列的计算,并通过for-in循环打印输出具体数列。
在Java中,惰性求值可以通过lambda表达式和Supplier接口实现,如下所示:
import java.util.function.Supplier;
public class Lazy {
public static int compute(int arg) {
return arg + 1;
}
public static void main(String [] args) {
int v1 = compute(42); // eager
System.out.println(v1);
Supplier<Integer> v2 = () -> compute(42); // lazy
System.out.println(v2);
System.out.println(v2.get());
}
}
和JavaScript中类似的,将求值的过程通过lambda表达式包装成函数,返回一个Supplier接口类型的对象。通过Supplier对象上的get()方法,可以获得实际的求值结果。
在C++中,我们可以用lambda表达式来实现惰性求值, 如下所示:
#include<iostream>
using namespace std;
int AddFunc(int a, int b)
{
return a + b;
}
int main(){
int sum = AddFunc(3,2);
cout<< sum << endl;
auto sum2 = []()->int{ return AddFunc(3, 2); };
cout << sum2() << endl;
return 0;
}
惰性求值通过避免不必要的计算节省计算资源。目前最流行的机器学习框架TensorFlow,使用了计算图来定义计算的过程,当需要知道计算图中具体的值时,才通过 session 执行构建过程中生成的图中的操作,因而TensorFlow的计算模式也是惰性求值的。
函数式编程的优点
函数式编程以声明式代替命令式的编程方法,抽象层次更高,更接近自然语言,代码简洁,易于理解。而且由于模块小,耦合低,所以易于测试和调试。另外由于这种函数式编程没有副作用,所以程序易于并发执行,也可实现代码的热升级。
单元测试
因为FP中的数据都是不可变的,于是没有什么函数会有副作用。谁也不能在运行时修改任何东西,也没有函数可以修改在它的作用域之外修改什么值给其他函数继续使用(在指令式编程中可以用类成员或是全局变量做到)。这意味着决定函数执行结果的唯一因素就是它的返回值,而影响其返回值的唯一因素就是它的参数。 这正是单元测试工程师梦寐以求的啊。现在测试程序中的函数时只需要关注它的参数就可以了。完全不需要担心函数调用的顺序,也不用费心设置外部某些状态值。唯一需要做的就是传递一些可以代表边界条件的参数给这些函数。相对于指令式编程,如果FP程序中的每一个函数都能通过单元测试,那么我们对这个软件的质量必将信心百倍。反观Java或者C++,仅仅检查函数的返回值是不够的:代码可能修改外部状态值,因此我们还需要验证这些外部的状态值的正确性。在FP语言中呢,就完全不需要。
调试查错
如果一段FP程序没有按照预期设计那样运行,调试的工作几乎不费吹灰之力。这些错误是百分之一百可以重现的,因为FP程序中的错误不依赖于之前运行过的不相关的代码。而在一个指令式程序中,一个bug可能有时能重现而有些时候又不能。因为这些函数的运行依赖于某些外部状态, 而这些外部状态又需要由某些与这个bug完全不相关的代码通过某个特别的执行流程才能修改。在FP中这种情况完全不存在:如果一个函数的返回值出错了,它一直都会出错,无论你之前运行了什么代码。 一旦问题可以重现,解决它就变得非常简单,几乎就是一段愉悦的旅程。中断程序的运行,检查一下栈,就可以看到每一个函数调用时使用的每一个参数,这一点和指令式代码一样。不同的是指令式程序中这些数据还不足够,因为函数的运行还可能依赖于成员变量,全局变量,还有其他类的状态(而这些状态又依赖于类似的变量)。FP中的函数只依赖于传给它的参数。还有,对指令式程序中函数返回值的检查并不能保证这个函数是正确运行的。还要逐一检查若干作用域以外的对象以确保这个函数没有对这些牵连的对象做出什么越轨的行为。对于一个FP程序,你要做的仅仅是看一下函数的返回值。
并发执行
不需要任何改动,所有FP程序都是可以并发执行的。由于根本不需要采用锁机制,因此完全不需要担心死锁或是并发竞争的发生。在FP程序中没有哪个线程可以修改任何数据,更不用说多线程之间了。这使得我们可以轻松的添加线程,至于那些祸害并发程序的老问题,想都不用想!
参考资料
- 《设计模式—可复用面向对象软件的基础》,作者: [美] Erich Gamma等,机械工业出版社
- 《Head First 设计模式》作者: 弗里曼,中国电力出版社
- 《JavaScript设计模式与开发实践》 作者:曾探,人民邮电出版社
- 《设计模式之禅》作者:秦小波,机械工业出版社. 2014
- 图说设计模式
- 《Functional Programming in JavaScript》, Dan Mantyla, PacktPub.
- Functional Proramming in C++
- 傻瓜函数式编程